随着物联网、移动互联网和工业互联网的迅猛发展,数据正以前所未有的速度和规模产生。海量流数据处理,即对持续不断、高速生成的数据流进行实时或近实时分析与处理,已成为驱动企业智能决策和业务创新的关键技术。在这一背景下,将海量流数据处理能力进行服务化封装,构建标准化、可复用、易扩展的数据处理服务,正成为产业界与学术界共同关注的焦点。
一、 海量流数据处理的核心挑战
传统的批处理模式在面对海量、实时、无序的数据流时显得力不从心。流数据处理面临吞吐量、延迟、准确性、状态管理和容错性等多重挑战。如何设计一个能够持续稳定运行、低延迟处理海量事件、并能保证结果准确性的系统,是首要难题。
二、 服务化:数据处理能力的新范式
“服务化”的核心思想是将复杂的技术能力封装成标准化的、通过网络接口(API)进行访问的服务。将海量流数据处理能力服务化,意味着:
- 解耦与复用:将数据接入、清洗、转换、分析、输出等处理逻辑封装成独立服务,业务应用无需关心底层复杂的技术实现,只需通过API调用所需的数据处理功能,极大地提升了开发效率和系统可维护性。
- 弹性与可扩展:服务化的架构天然支持水平扩展。面对波动的数据流量,可以动态调整服务实例的数量,实现资源的弹性伸缩,既保障了处理性能,又优化了成本。
- 标准化与集成:统一的API接口和协议(如RESTful、gRPC)使得不同团队、不同系统能够轻松集成和使用流数据处理能力,促进了企业内部的数据协作与生态构建。
- 运维与治理:集中的服务管理平台可以方便地对数据处理服务进行监控、告警、版本管理和生命周期控制,提升了整体系统的可靠性与可运维性。
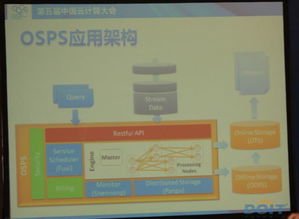
三、 数据处理服务化的关键技术架构
一个成熟的海量流数据处理服务化平台通常包含以下层次:
- 基础设施层:提供计算、存储和网络资源,通常基于云原生技术(如Kubernetes)实现资源的动态调度与管理。
- 流处理引擎层:集成或自研核心流处理引擎(如Apache Flink、Spark Streaming、Kafka Streams),负责高吞吐、低延迟的数据处理计算。
- 服务化封装层:这是实现“服务化”的关键。它将流处理作业(Job)抽象为“服务”。通过定义服务模板、配置处理逻辑(如SQL、UDF或自定义代码)、指定输入输出源(如Kafka、MQTT、数据库),将一个数据处理流水线打包成一个可部署、可调度的服务实例。
- API网关与管理控制层:对外提供统一的API访问入口,负责认证、鉴权、限流和路由。对内提供可视化的控制台,用于服务的设计、部署、启停、监控和运维。
- 数据源与输出集成层:提供丰富的连接器(Connectors),支持与各类消息队列、数据库、文件系统和外部API进行无缝数据对接。
四、 实践场景与价值体现
数据处理服务化已在众多场景中发挥巨大价值:
- 实时风控:在金融交易或在线支付中,将交易数据流实时送入风控规则服务,毫秒级内识别并阻断欺诈行为。
- 物联网监控:对百万级设备上报的传感数据流进行实时聚合与分析服务,即时发现设备异常并预警。
- 实时推荐:将用户点击、浏览行为流与模型预估服务结合,实现动态的个性化内容推荐。
- 运营大盘:将各业务线的日志和事件流通过数据清洗、聚合服务,实时生成可视化的业务运营仪表盘。
在这些场景中,服务化模式使得业务团队能够像“点菜”一样,快速组合和调用所需的数据处理功能,将开发周期从周/月级缩短至天/小时级,真正让数据能力赋能业务敏捷创新。
五、 未来展望
海量流数据处理的服务化将朝着更智能、更融合的方向演进:
- Serverless化:进一步抽象底层资源,开发者只需关注数据处理逻辑,平台实现完全的自动扩缩容与按需计费。
- AI融合:将机器学习模型的训练与推理过程无缝嵌入流处理服务链,实现实时智能决策。
- 统一批流服务:提供统一的API和服务框架,让用户无需区分批处理和流处理,实现真正的一体化数据处理体验。
以孙冰等专家和从业者为代表的探索与实践表明,将海量流数据处理能力服务化,不仅是应对当前数据挑战的有效手段,更是构建未来企业智能化数据基础设施的基石。它通过降低技术门槛、提升开发运维效率,最终目标是让数据如水、电一般,成为随时可取、随处可用的基础服务,源源不断地驱动业务价值创造。









